
![]() This is the most widely varied and exciting set of student cluster competition systems I’ve seen since the competition began ten years ago. We have fourteen different teams and fourteen different takes on which system configuration is best suited to take on the applications in this year’s competition.
This is the most widely varied and exciting set of student cluster competition systems I’ve seen since the competition began ten years ago. We have fourteen different teams and fourteen different takes on which system configuration is best suited to take on the applications in this year’s competition.
We’re seeing some changes from previous competitions. Average node counts are down significantly from 6.5 nodes and 9 nodes per team at the last ISC and ASC competitions to 4.2 nodes (when the outlying 37-node FAU system is subtracted).
We’re also seeing accelerator usage spiking, with the average team using 7.9 accelerators (almost all GPUs) versus 6.8 at the International Supercomputing Conference (ISC’16) and 4.0 at the Asian Student Cluster Competition (ASC16).
Average memory per cluster this year is down, with students running 760 GB per system at SC16 versus 1.1 TB at ASC16 and 948 GB per system at ISC16. Interesting trends indeedy…
It’s all over the map this year. Let’s go through it team by team (click image to enlarge)…
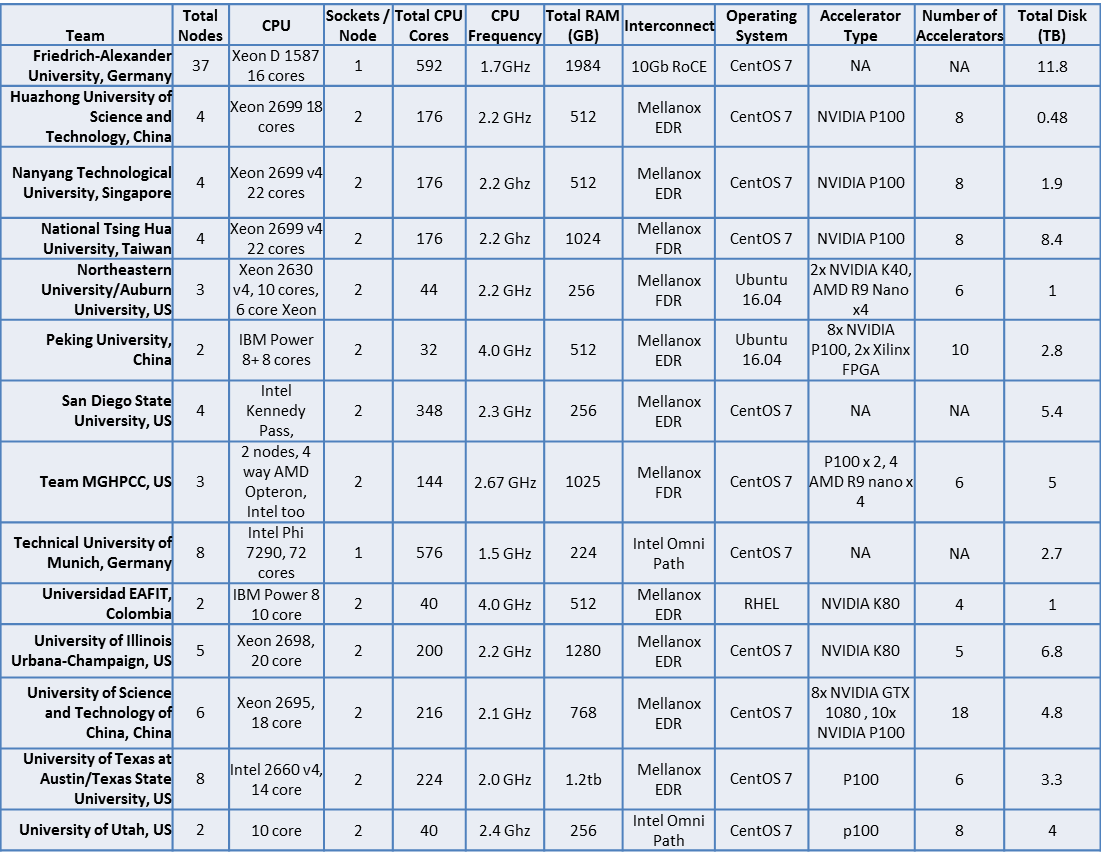
FAU: This is the third competition for Friedrich-Alexander University, Germany, and the first time they’re running an unaccelerated cluster. The team is hoping that having a lot of CPU cores (592) and the most memory (by a large margin) will give them the upper hand on the applications.
They’re using the highly modular HPE Moonshot system, equipped with 37 nodes of ProLiant M510 server cartridges. Like most teams, they’ll be throttling down their processors in order to stay under the 3,000 watt power cap. Interconnect wise, the team is utilizing the integrated 10GbE RoCE, which gives them the ability to use RDMA over Ethernet.
HUST: This team from Huazhong University of Science and Technology won the ASC16 cluster competition in their hometown of Wuhan. Huazhong is using their standard time-tested configuration of four Xeon nodes plus eight accelerators.
This is same basic configuration that gave them the win at ASC16 and punched their ticket to ISC’16. The major difference is that they’re using NVIDIA P100s rather than K80, which should give their cluster a lot more punch. The HUST team is sporting the least amount of disk in the competition, giving them a bit more power to use for processing, but shorting them on disk capacity when it comes to application storage and check-pointing.
Nanyang: This veteran Singapore-based team from Nanyang Technological University won the LINPACK battle at ASC16 so they’ve tasted the sweet nectar of victory and are hungry for more. They seem to favor smaller node counts with lots of accelerators, which tends to make me think they’re again aiming for the LINPACK title.
At SC16, they’re running a Dell four-node box with 176 CPU cores, and a total of eight NVIDIA P100s, with 512GB of memory. It’s all tied together with speedy 100Gbps Mellanox EDR InfiniBand, which is what most teams are using these days. Nanyang is a team to keep an eye on, they feel like they’re ready to break out of the pack.
NTHU: National Tsing Hua University from Taiwan is another university that has participated in plenty of cluster competitions and has notched more than their share of victories.
NTHU was one of the first teams to win with accelerators and is always a solid competitor. They typically sport eight-node systems, but this year, they’re slimming down with a four-node sportster. Like other teams, they’re augmenting their 176 CPU cores with eight NVIDIA P100 GPUs. They’ve also configured an above average amount of memory with 1 TB total.
NE/Auburn: The combined team of Northeastern University and Auburn University turned out to be the one to suffer significant hardware problems at the SC16 competition.
In this case, “significant” problems turned out to be their entire cluster lost in shipping. They were forced to scour the show floor to find enough systems to cluster up, which they did very well.
Unfortunately, they ended up with a small mishmash of three boxes that yielded 44 CPU cores, some memory, four NVIDIA K40 accelerators, and four AMD R9 Nano accelerators. They did a hell of a job putting all of this together at the last minute and being able to run all of the applications – so hats off to them for showing the real Student Cluster Competition spirit.
Peking University: Now this is a team that’s breaking barriers when it comes to cluster competition hardware. They are the first team to run with the whole schmear of OpenPOWER gear. Their cluster consists of dual nodes fuelled by dual Power 8+ processors running at 4GHz for a total of 32 CPU cores.
What’s really exciting is that this system includes the NVIDIA NVLink connector to give Peking’s 10 (TEN) P100 GPUs an up to 80GBps connection directly to the CPUs. But the team didn’t stop there. They added dual Xilinx FPGAs in order to help out with the password-cracking application. This is one hell of an accelerated system and it’ll be interesting to see how it does in the competition.
San Diego: This is the first student cluster competition for the San Diego State University. The Aztec Warriors are driving an Intel Kennedy Pass motherboard-based system with four nodes and 348 CPU cores on the compute node (28 cores on the head node). The system is rounded out with 256 GB total memory and an Mellanox InfiniBand FDR interconnect.
MGHPCC: A perennial competitor, Massachusetts Green HPC Center is a combined team from several Boston-area universities. They’ve also been dubbed (by me) “Team Boston” or “Team Chowder”.
Some of the team members competed at this year’s ASC, where they were initially confounded by InfiniBand. This year, the team seems much more comfortable with this technology, using it to drive their three-node cluster. Their system this year should be called “the unity cluster” since it’s a combination of AMD Opteron and Intel Xeon nodes. They’ve also cobbled together dual NVIDIA P100 GPUs and four AMD R9 Nano accelerators. Like the team itself, it’s quite an eclectic bunch of equipment.
TUM: The Technical University of Munich is another team that’s setting new precedents in the cluster competition. They’re the first to field a cluster entirely made up of Intel Knights Landing processors – used in host mode.
Their cluster consists of eight one-socket nodes, each with one 72 core Phi processor running at 1.5 GHz. They’ve gone all in with Intel, using Omni Path Architecture as their interconnect. As you’ll see in the upcoming team video, they’ve also started a “Phi Club”, complete with rules (the first two being “you must talk about Phi Club”).
EAFIT: The Universidad EAFIT team from Colombia is rapidly becoming one of the most experienced in the competition. I’ve seen this version of the team at ASC, ISC, and SC competitions over the past few years.
This year, they are driving a OpenPOWER 8-based cluster complete with four NVIDIA K80s and a speedy Mellanox EDR interconnect. While the processors and interconnect are pretty fast, bringing the venerable K80 to SC this year is like bringing a knife to a machine gun fight. I’m not sure the plucky kids from Colombia have fast enough hardware to hang with the big boys. Experience counts for a lot in student clustering, but it can’t overcome a lack of hardware.
Illinois: The team from University of Illinois, Champaign-Urbana (or Urbana-Champaign, according to the team) is another first-time competitor. They’re running a fairly standard cluster with five compute nodes, each outfitted with dual Xeon 20 core processors (total 200 cores), a NVIDIA K80 GPU, and 256 GB of RAM. They have a decent enough cluster, but are a bit weak when it comes to accelerators in comparison to other teams.
USTC: The University of Science and Technology of China is really bringing it this year. This will be their third cluster competition and it looks like they’re going all out to either take LINPACK or break the power monitors on the PDUs. Their six-node system is jam-packed with 216 CPU cores and 18 (eighteen!) NVIDIA accelerators. They’re sporting ten P100s and eight GTX 1080s. The rationale is that the P100s will help them out with LINPACK and general application processing, while the GTX 1080s will be particularly useful for the rendering associated with the Paraview application. This is a LOT of hardware – we’ll see if it can take them to glory.
Texas: This team is a combination of students from the always powerful University of Texas at Austin and Texas State University programs. As all cluster competition aficionados know, the Austin team was the first to three-peat at SC cluster competitions – a feat yet to be duplicated. However, they’re sporting all-new personnel, although it does have highly experienced coaches.
Their cluster is a bit of a departure for the Texas team. In past competitions, they’ve shied away from accelerators, figuring that the applications just weren’t accelerator-centric enough to justify their use. This year, however, the team is using six NVIDIA P100s to accompany their eight-node, 224-core system. Will this approach take the Lone Star State back to their past glory?
Utah: The University of Utah is the home team this year, since the competition is being held on their doorstep in Salt Lake City. This Dell backed team is driving a smallish two-node cluster with only 40 CPU cores. For extra compute power, each node is stocked with dual NVIDIA P100s.
The team is also using Intel’s Omni Path interconnect to link their two nodes together. As the team points out in their proposal, using only two nodes allows them to minimize internode communication – which is absolutely true – but does this give them enough compute power to challenge for the title?
In our next updates we’ll meet the teams via the miracle of video, discuss the LINPACK results, show some more video content, then slice/dice and analyse the overall results. So stay tuned for more…
Posted In: Latest News, SC 2016 Salt Lake City
Tagged: supercomputing, Student Cluster Competition, HPC, University of Science and Technology of China, National Tsing Hua University, Huazhong University of Science & Technology, The University of Texas at Austin, Northeastern University, Nanyang Technological University, Universidad EAFIT, Friedrich-Alexander-Universitat Erlangen-Nuremberg, SC16, Auburn University, Peking University, San Diego State University, Massachusetts Green HPC Center, Technical University of Munich, University of Illinois Urbana-Champaign, Texas State University, The University of Utah, SC 2016