
The biggest benchmark the student warriors tackled during the ISC19 Student Cluster Competition was the colossal HPC Challenge. This is a collection of benchmarks that has a little something for everyone from memory bandwidth fans to those who can’t get enough raw number crunching. The HPC Challenge benchmark is run as a single job. However, there are some limited ways to optimize and tune the benchmarks before you run them.
We consulted a long-time HPC expert who bills himself as a “former slimy benchmarker” who knows the ins and outs of benchmarking and has used them for both good and evil. When contacted, he said that students have to intimately know the Three Rules of Benchmarking:
“The first rule of benchmarking is read the rules; the second rule of benchmarking is read the rules. And the third rule of benchmarking is to obey the first two rules.”
With that sage advice, let’s take a look at the detailed student scores for HPCC…
 HPL is an old friend to most benchmarkers: they know it, they love it. Or at least know how to work it. While the students run LINPACK to qualify for the Highest LINPACK award, they run it again as part of the HPCC benchmark.
HPL is an old friend to most benchmarkers: they know it, they love it. Or at least know how to work it. While the students run LINPACK to qualify for the Highest LINPACK award, they run it again as part of the HPCC benchmark.
CHPC narrowly beat out EPCC for a win on HPL, with Nanyang coming in third place. The average and median scores for the field are kind of low, which is a bit of a surprise to me since the students have had so much practice on it.
![]() P-TRANS is a benchmark that measures the rate at which a system can transpose a large matrix on its diagonal. Depending on the size of the matrix, this can be pretty demanding computationally. It’s possible, and within the HPCC rules, to use a linear algebra library, like BLAS, to optimize the process.
P-TRANS is a benchmark that measures the rate at which a system can transpose a large matrix on its diagonal. Depending on the size of the matrix, this can be pretty demanding computationally. It’s possible, and within the HPCC rules, to use a linear algebra library, like BLAS, to optimize the process.
CHPC scored another win on P-TRANS with a score of 49.42 GB/s, well ahead of ETH Zurich’s score of 43.51. University of Hamburg makes their first appearance on the leaderboard with their third place finish. Tsinghua earns an honorable mention for their score of 35.76. All of our top finishers were way above the average and median scores for P-TRANS.
 Random Access measures how quickly the system can access memory pages, loading page after page of memory. This one isn’t so much about tuning as it is about having a hardware set up that has good memory characteristics, such as fast DIMMs and low latency. It also helps to have a single DIMM per memory channel. Our former slimey benchmarker says: “Nothing they can do on this except set up for big pages, if they know how to do that – which they certainly should, in my opinion.”
Random Access measures how quickly the system can access memory pages, loading page after page of memory. This one isn’t so much about tuning as it is about having a hardware set up that has good memory characteristics, such as fast DIMMs and low latency. It also helps to have a single DIMM per memory channel. Our former slimey benchmarker says: “Nothing they can do on this except set up for big pages, if they know how to do that – which they certainly should, in my opinion.”
Sun Yat-Sen schooled the rest of their field with their dominating score of 1.1 Gup/sec, which is a serious number of giga updates. Nanyang pulled second place with a score of .50 and Tsinghua was well back with .35 to take third. EPCC earns a mention because their score was well above the average and median scores, nice job.
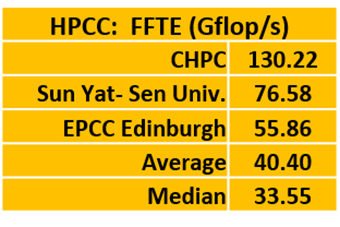 FFTE (Fast Fournier Transform): FFTE is an algorithm that converts a signal, usually time or space, into a value in a frequency domain. FFTE is often used in engineering, science and mathematics. “Depending on the matrix size, a FFTE library could improve performance, but they don’t know the matrix size coming in, so too bad….”says our slimy benchmarker.
FFTE (Fast Fournier Transform): FFTE is an algorithm that converts a signal, usually time or space, into a value in a frequency domain. FFTE is often used in engineering, science and mathematics. “Depending on the matrix size, a FFTE library could improve performance, but they don’t know the matrix size coming in, so too bad….”says our slimy benchmarker.
CHPC dominated FFTE by more than doubling the score of the second-place Sun Yat-Sen. EPCC Edinburgh got on the board with a distant third-place finish.
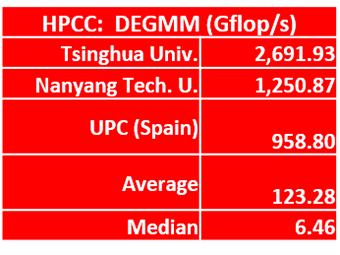 DEGMM: This is a benchmark that multiplies matrices, which is a lot of multiplication as it turns out. Our slimy bench marker says “you can’t do much on DEGMM and stay within the rules, but you can use different compilers and different options within the compilers to find the optimal set for their machine.”
DEGMM: This is a benchmark that multiplies matrices, which is a lot of multiplication as it turns out. Our slimy bench marker says “you can’t do much on DEGMM and stay within the rules, but you can use different compilers and different options within the compilers to find the optimal set for their machine.”
It looks like Tsinghua did exactly that and it paid off. Their score of 2,691.93 was more than double that of second-place Nanyang Tech. Our buddies from UPC make the leaderboard with their 958 score, which is a pretty damned good result for a team that’s driving Arm processors. Great job.
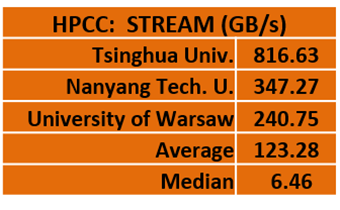 STREAM is a memory bandwidth test. According to our slimy benchmarker, “…more and faster DIMMs are key here, and big pages will make a difference. Need to have a DIMM in every DIMM slot and a motherboard that can drive them.”
STREAM is a memory bandwidth test. According to our slimy benchmarker, “…more and faster DIMMs are key here, and big pages will make a difference. Need to have a DIMM in every DIMM slot and a motherboard that can drive them.”
Tsinghua, a team that had the highest performance cluster in our evaluation, handily grabbed the STREAM crown by dominating the rest of the field with their score of 816 GB/s. Nanyang took second place with their score of 347.27. The Warsaw Warriors put themselves on the board with a third-place score of 240.74, despite driving a brand new architecture, the NEC Aurora vector system.
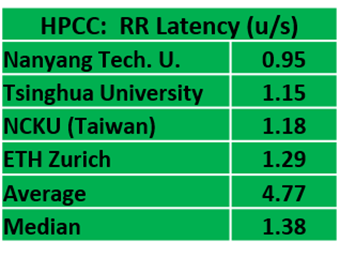
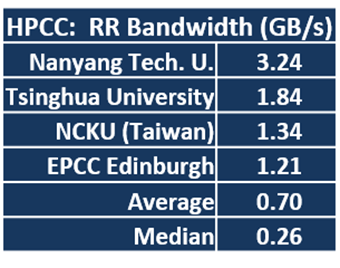 Random Ring Bandwidth is a test of MPI bandwidth that measures two cases of MPI bandwidth: 1) a non-simultaneous ping pong that tests MPI bandwidth with no contention
Random Ring Bandwidth is a test of MPI bandwidth that measures two cases of MPI bandwidth: 1) a non-simultaneous ping pong that tests MPI bandwidth with no contention
, and 2) a simultaneous communication that uses random and ring patterns to measure bandwidth with MPI contention.
Random Ring Latency tests the latency of system communications using the same mechanisms as the bandwidth test.
In the bandwidth test, the higher the score, the better. In the latency test, lower is better.
In the ISC19 HPCC benchmark, Nanyang Tech is the Lord of the Rings, taking the top scores in both benchmarks. Tsinghua took second in the ring tests. The team from NCKU, which has the most rudimentary cluster in the competition (although it’s the best price-performer), grabbed third in both tests, putting them on the big board for the first time. EPCC took fourth in the bandwidth test while ETH Zurich took fourth on the latency test.
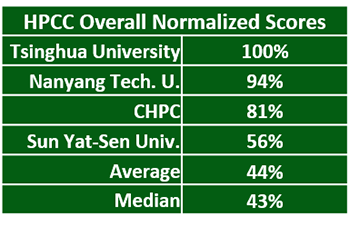 The overall scores tell the story as Tsinghua grabs the top slot with a 100% normalized score and adds a full 10 points to their competition tally. Nanyang grabs second place and 9.4 points. CHPC and Sun Yat-Sen finish a distant third and fourth , but still get their share of points.
The overall scores tell the story as Tsinghua grabs the top slot with a 100% normalized score and adds a full 10 points to their competition tally. Nanyang grabs second place and 9.4 points. CHPC and Sun Yat-Sen finish a distant third and fourth , but still get their share of points.
While this is a mega-big benchmark, in the whole scheme of things it only counts for 10% of the total competition score – not enough to give anyone an insurmountable advantage or disadvantage. But it’s fun to look at the deep results and highlight the individual performance of the teams.
Quick plug: check out the Student Cluster Competition Leadership List and see where your favorite team ranks. This is a joint project between the HPC-AI Advisory Council and me and is the culmination of many years of painstaking tracking and research. The list shows every team to ever compete in a Student Cluster Competition and assigns points based on their participation and awards. There are four different cuts of the data, the first being a worldwide ranking, then separate rankings for EMEA, the Americas, and APAC. It will be updated after every competition and more features will be added over time.
In our next articles we’ll be looking at the HPC application scores and then looking at the day-by-day results to show you who won and how they won. Stay tuned….
Posted In: Latest News, ISC 2019 Frankfurt