
With the dust settling on the ISC’13 Student Cluster Challenge, it’s a good time to look back and take stock and see what we’ve learned.
While traveling recently, I found myself unable to type on my laptop keyboard (the idiot in front of me reclined into my lap), but I could use the handy track point ‘nub’, so I fired up a spreadsheet and did some one-finger analysis. I was curious to see what role cluster configuration might have played in the final competition results. (I used a different finger to express my feelings about the guy in 24F.)
The ISC Student Cluster Challenge is a series of “sprints” requiring students to run HPCC and a variety of HPC applications over a two-day period. They work on one application at a time, tuning and optimizing it to maximize throughput. And they can’t just throw more hardware at the problem – there’s a hard power cap of 3,000 watts.
With this in mind, let’s take a look at how the various student clusters stacked up against each other and see if we can glean any insight. There was a lot of commonality between the teams, with all of them using Mellanox Infiniband interconnects and switches, and most running RHEL. But there were some major differences, which I’ve summarized on the charts below…
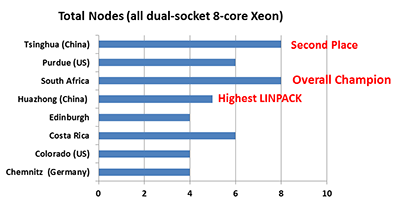
There are some clear differences in node count (above) and core count (below) in the 2013 competition.
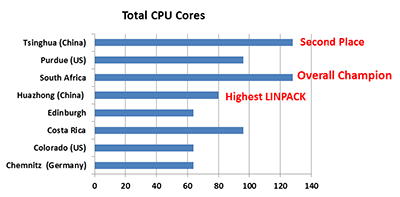
South Africa and Tsinghua clearly have both more nodes and more cores than their fellow competitors, which certainly seemed to give them an advantage in terms of application performance.
We also see that there’s quite a bit of difference when it comes to total memory; Tsinghua weighed in with a whopping 1TB.
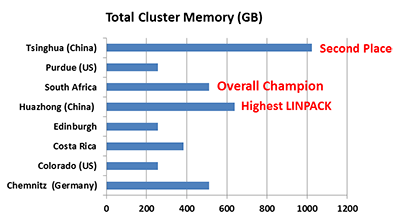
Based on what I know about the scores for the individual applications, it looks like Tsinghua’s massive memory gave them an advantage over the rest of the field, but not quite enough of an advantage to take the overall win.
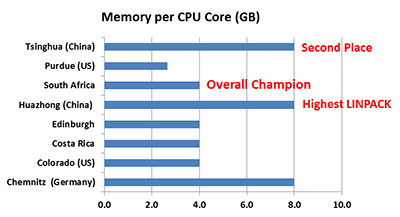
Tsinghua, Huazhong, and Chemnitz have double the RAM per core of other competitors, which certainly had a positive effect on performance. On the other hand, South Africa turned in solid app performance using less memory per core, but a large number of cores.
This is the first competition in which every team has used some kind of compute accelerator. Most went with NVIDIA Kepler K20s, while Colorado and Purdue tried the new Intel Phi co-processor on for size.
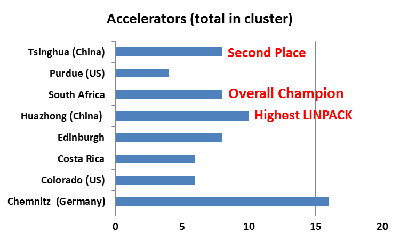
One team, Germany’s own Chemnitz, went wild on accelerators. They configured eight Intel Phi and eight NVIDIA K20s into their cluster. While this gave them a hell of a lot of potential compute power, it also consumed a hell of a lot of electricity.
Difficulties also arose when the team tried to get both accelerators running on the same application, so they ended up running particular apps on the K20s and others on the Phis. The problem is that even when they’re idled, these beasts consume significant power and generate heat as well. Chemnitz put together a monster cluster, but like most monsters, it couldn’t be completely tamed.
Lessons Learned
So what have we learned? I think it’s safe to say that more nodes and cores are better than fewer – now there’s a blinding glimpse of the obvious, eh? There is also a relationship between lots of memory and higher performance: again, an obvious conclusion.
However, we see that more accelerators aren’t necessarily more better. The winning teams had one accelerator per node, with Huazhong landing the top LINPACK with two accelerators per node.
All of the top teams were running NVIDIA K20s rather than Intel’s Phi co-processor, but we can’t put too much weight on this first NVIDIA vs. Intel showdown. This was the first time students had a chance to use Phi, and they didn’t get all that much time to work on optimization prior to the competition. The upcoming cluster showdown at SC13 in November will probably give us a better view of comparative performance.
Posted In: Latest News, ISC 2013 Leipzig
Tagged: supercomputing, HPC, LINPACK, GPU, NVIDIA, CPU, ISC 2013, Intel, Student Cluster Challenge, accelerators, Results