
 More than 230 university teams vied for only 20 slots in the 2017 Asian Student Cluster Competition (ASC) finals being held this week in Wuxi, China. At 20 teams, this is the largest cluster competition the world has ever seen. Really, it is.
More than 230 university teams vied for only 20 slots in the 2017 Asian Student Cluster Competition (ASC) finals being held this week in Wuxi, China. At 20 teams, this is the largest cluster competition the world has ever seen. Really, it is.
Each team consists of five undergrads and a coach, who is usually a faculty advisor. The kids design their own cluster, optimize their software, and then race against the other teams live at the ASC event. The team with the best performance on all of the benchmarks and applications is crowned the overall champion. There are also prizes for the silver medal finisher, highest LINPACK, and best optimization of various applications.
As usual, the slate of teams consists of a heady mix of battle-hardened veterans and starry-eyed newcomers. New teams this year include: Ocean University of China, St Petersburg University from Russia, the PLA Information Engineering University from China, Southeastern University of China, the University of Warsaw, and China’s Weifang University.
Let’s take a quick look at the teams and their configurations:
(Click image to enlarge.)
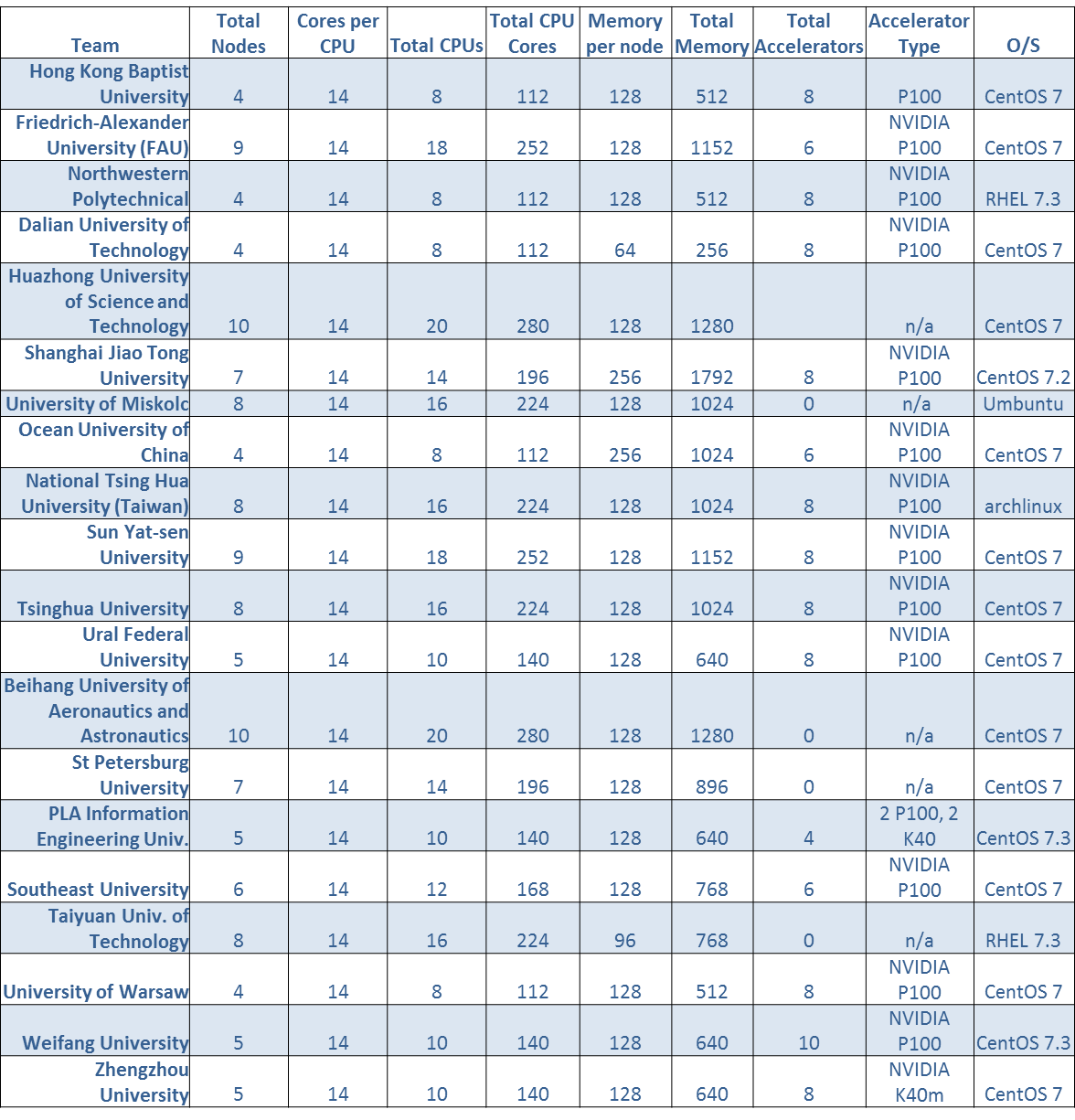
While we don’t have the time (or space) to go into depth on each and every one of the 20 teams and why they made their architectural decisions, we can look at the configs in aggregate and pull out some insights.
Node count: It used to be easy to see what award a team was going after just by looking at their node count. The teams with very low node counts would have high numbers of accelerators (at least two per node) and thus were typically aiming for the highest LINPACK prize. Teams with more nodes and fewer (or no) GPUs or other accelerators were typically trying for the overall championship prize.
I need to do some research to back this up, but I have a hunch that the average node count (6.5 nodes at ASC17) is slowly dropping over time. This is a signal that GPU-accelerated nodes are steadily reducing the numbers of CPUs deployed in the typical student cluster.
What’s different today is that more applications are optimized for GPU accelerators and thus the small node count teams are in the running for the overall championship award. It’s the larger, more traditional CPU-only systems that are starting to look a bit long in the tooth performance-wise.
CPU Cores: While everyone is using the same 14 core Intel Xeon CPU, they’re using different quantities of them, which is what gives us a range of CPU core counts varying from only 112 on the low end up to 180 on the high side.
Memory per node/total memory: I always thought that the more memory you can throw into these boxes, the better. But I’m not so sure these days. Again, the rise of uber-fast accelerators is starting to change what you need to be competitive in these cluster battles. Massive numbers of CPUs accompanied by equally massive amounts of RAM aren’t getting the job done as well as they did just a few years ago.
In this competition, we see a very wide range of total cluster memory from only 265GB (Dalian University) to a massive 1.28TB on the Beihang cluster. What I’ll be looking for is how systems configured with the same number of CPUs/GPUs but different amounts of memory compare on application performance.
Accelerators: The GPU Fairy was very kind to the students at this year’s ASC17 competition. How kind? Well, 15 of the 20 teams competing at ASC17 are using some sort of GPU-based accelerator, with 13 of those 15 sporting shiny new NVIDIA P100s. I figure that’s somewhere around $750,000 street value worth of GPUs, which is pretty cool.
As we saw at SC16, the addition of the P100s resulted in an almost tripling of the highest LINPACK score, rising from the 12TF level to 31TF/s. Will we see a new record at this year’s ASC? And will we see fancy FPGAs in future competitions?
Stay tuned for more coverage. Next up is the LINPACK results, our video introduction to the teams, and more application results. Check back often for updates.
Posted In: Latest News, ASC 2017 Wuxi
Tagged: supercomputing, Student Cluster Competition, ASC17, ASC 2017